SEO w czasach Web 1.0 i Web 2.0
Za początek SEO można uznać 1990 rok, w którym opublikowana została pierwsza statyczna strona www co dało początek World Wide Web 1.0. Web 1.0 to okres statycznych treści bez interakcji z użytkownikiem. 2005 rok to początek Web 2.0, który opiera się na społecznościach i interkacjach pomiędzy użytkownikami w sieci, co daje początek UGC (User-generated Content), czyli contentu tworzonego przez użytkownika.
Dość często spotykam się z określeniem “SEO się kończy” lub “SEO umiera”. Obserwując z bliska zmiany w wyszukiwarce i jej algorytmach utwierdzam się w przekonaniu, że SEO wzrasta i wzrastać będzie, ale jest to już inne SEO. Z pewnością wraz z końcem Web 2.0 i początkiem Web 3.0 zakończyła się pewna epoka SEO opartego na słowach kluczowych i budowaniu lichej jakości backlinków i zaplecz. Optymalizacja to znacznie więcej niż zapewnienie obecności kilku znaczników ważnych dla SEO przeładowanych wystąpieniami słów kluczowych.
Początkiem zmian było wprowadzenie w 2011 roku danych strukturalnych opisujących elementy strony, a następnie kolejnych algorytmów, takich jak Koliber związany z przetwarzaniem języka naturalnego (NLP), RankBrain (2015), Neural matching (2018) wykorzystujący sieci neuronowe (AI) aż po algorytm Bert (2019), który był skupiony na zrozumienie kontekstu.
Web 3.0 a SEO
W 2022 roku na konferencjach i szkoleniach związanych z SEO w tematach wystąpień dominują takie zagadanienia, jak #semantyka #wyszukiwaniesemantyczne #intencje #entities #web3.0 #nlp #topicalauthority #konowledgegraph #grafwiedzy #mum #richsnippets #serpfeatures
Web 3.0 jest oparty na semantycznej sieci internetowej (Semantic Web) używanej do lepszego zrozumienia treści z wykorzystaniem AI oraz nowych sposobów konsumowania ich konsumowania od rozszerzonej rzeczywistości po wirtualną rzeczywistość i metaverse itd. Powstają już pierwsze wyszukiwarki dedykowane Web 3.0, takie jak Cyber. Google dbając o core swojego biznesu stara się podążać za dynamiką zmian i wdrażać mechanizmy mające na celu poprawę dokładności wyświetlanych wyników wyszukiwania.
W poniższym artykule chciałbym przybliżyć te mechanizmy.
Czym jest wyszukiwanie semantyczne?
Wyszukiwanie semantyczne, to proces zrozumienia zapytania użytkownika kierowanego do wyszukiwarki w celu zaprezentowania jak najdokładniejszej odpowiedzi w wynikach wyszukiwania.
Dzięki wyszukiwaniu semantycznemu Google stara się zrozumieć intencję i kontekst poprzez analizę powiązań pomiędzy poszczególnymi słowami tego zapytania.
Semantyka jest nauką lingwistyczną, która bada znaczenie i konotacje wyrażeń poprzez rozkładanie ich na mniejsze jednostki. Jest ona kluczowa w podejściu wyszukiwarki Google, który stara się sprawdzić kontekst zapytania i potrzebę użytkownika. Celem procesu analizy zapytania jest wyświetlenie wyniku wyszukiwania spełniającego intencje użytkownika.
Jak rozpoznać intencje użytkownika?
Jeśli mowa o intencjach, to musimy pamiętać, że najważniejszą intencją użytkownika jest przede wszystkim szybki dostęp do informacji.
Użytkownicy oczekują precyzyjnej odpowiedzi na zapytanie w możliwie jak najszybszym czasie. Potrzeba użytkowników zrodziła w Google pomysł wdrożenia wyników rozszerzonych, tzw. snippetów, które pozwalają na wyświetlanie odpowiedzi bezpośrednio w wynikach wyszukiwania.
Google wyróżnia następujące intencje:
- Know – chęć poszerzenia wiedzy przez użytkownika
- Know-simple – prosta i szybka odpowiedź, której oczekuje użytkownik
- Do – wykonanie akcji, takie jak pobranie, zakup
- Website – zamiar odwiedzenia strony
- Visit-in-person – chęć odwiedzenia fizycznego miejsca
Obserwacja wyniku wyszukiwania na konkretne zapytanie może sugerować nam intencje tego zapytania, ale nie musi zwłaszcza w przypadku intencji niejednoznacznych, tzw. intencji mieszanych. Przykładem intencji mieszanej będzie zapytanie “mars”, które ma wiele znaczeń: planeta układu słoneczniego, rzymski bóg wojny, czy producent czekolady Mars Wrigley i popularny baton Mars. Poniżej znajduje się tabela z przyporządkowanymi intencjami, które wyróżnia Google na odpowiadające im snippety. Warto zwrócić uwagę na zapytania, w których występują wyrazy charakterystyczne i sugerujące nam odpowiadającą im intencje.
Brak dopasowania do intencji to brak widoczności w wynikach wyszukiwania. Pierwszym celem jest więc dopasowanie do intencji użytkownika, co pozwoli na wzięcie czynnego udziału w wyświetleniach w wynikach organicznych. Google stara się określać intencję użytkownika poprzez śledzenie jego lokalizacji, profilu demograficznego, zachowania użytkownika (czynniki behawioralne) w wynikach wyszukiwania, historii wyszukań oraz wszystkich wykorzystywanych algorytmów i modeli opartych na NLP i AI, takich jak Koliber, RankBrain, czy Bert.
Jednym z przykładów z mojego podwórka była praca z blogiem o tematyce ochrony zasobów wodnych w konkretnym regionie Polski. Starałem się bezskutecznie zbudować widoczność jednego z artykułów na frazę “nazwa regionu + powódź”. W swoim artykule poruszałem tematy związane z zapobieganiem powodzi w tym regionie przy czym wszystkie artykuły z TOP10 pozycji na tę frazę opisywały powódź, która w tamtym regionie miała miejsce dziesiątki lat temu. To był główny powód mojego niepowodzenia. Po przeredagowaniu treści zaledwie w ciągu 2 tygodni z pozycji 50+ uzyskałem pozycje w TOP10.

Google zaczął postrzegać zawartość serwisów przez pryzmat pojęć, a nie słów kluczowych. Tymi pojęciami są wspomniane wyżej Entities.
Czym są Entites w SEO?
Część słów zawartych w zapytaniach użytkownika Google klasyfikuje jako Entites. Entites to podmioty/pojęcia, które mają swój unikalny ID. Poprzez zastosowanie mechanizmów wyszukiwania semantycznego Google rozbija zapytania użytkowników na mniejsze jednoski identyfikując poszczególne Enitites. Google w taki sam sposób analizuje teksty, które znajdują się w naszych serwisach. Google rozumie intencje, a więc frazy nie muszą występować w treści dosłownie, wystarczy, że wpisują i realizują intencję, czyli wyczerpują treść na dane pojęcie, które jest zapytaniem.

Jako przykład posłużę się zapytaniem “Kopernik”, które ma wiele znaczeń. Fraza ta ma wiele kontekstów, m.in. persona wybitny astronom Mikołaj Kopernik, Centrum Nauki Kopernik, fabryka cukiernicza Kopernik, muzeum im. Mikołaja Kopernika, tytuł filmu oraz inne liczne instytucje, takie jak szkoły, których jest patronem. Każde znaczenie jest w rzeczywistości unikalnym bytem, a dla Google unikalną Entity, która posiada unikalny ID.
Poniższe tabele pokazują wyniki sprawdzenia cech i atrybutów Entities dla fraz “Kopernik” i “Mikołaj Kopernik” poprzez interfejs API Knowledge Graph Search.
| id | typ | nazwa | opis | scoring |
| kg:/m/01vvm4 | Person | Nicolaus Copernicus | Methematician | 476 |
| kg:/m/0jkvqtj | Organization | Kopernik | Non-profit organization | 119 |
| kg:/m/0dd90b9 | Movie | Copernicus | 1973 film | 51 |
| kg:/m/02rpfhc | City, Place | Koperniki | Village in Poland | 49 |
| id | typ | nazwa | opis | scoring |
| kg:/m/01vvm4 | Person | Nicolaus Copernicus | Methematician | 11427 |
| kg:/g:121_twml | Place, School | High School in Cieszyn | School | 647 |
| kg:/g/120pnpzc | Thing | MS Mikołaj Kopernik | Vessel | 46 |
| kg:/g/06k3jbr | Book | Mikołaj Kopernik jako lekarz | Book by Nicolaus Copernicus | 25 |
Intencją dominującą jest osoba, która ma wysoki scoring w przypadku obu analiz. Próba osiągnięcia wysokiej pozycji na zapytanie “Kopernik” z artykułem dotyczącym promocji fabryki cukierniczej Kopernik będzie więc bardzo karokołomnym zadaniem.
Jeśli chcesz samodzielnie przeszukać grafy wiedzy Google pod kątem informacji o cechach i atrybutach konkretnych Entities możesz skorzystać z możliwości wypróbowania działania interfejsu API przeszukiwania grafu wiedzy (Knowledge Grapg Search API) dostępnego pod adresem *https://developers.google.com/knowledge-graph/reference/rest/v1*
Czym jest i jak działa graf wiedzy Google?
Graf wiedzy określa relację pomiędzy encjami. Jest to baza wiedzy o encjach oraz zachodzących między nimi relacjami. Wszystkie Entites łączą relacje w zależności od ich znaczeń, kontekstu czy intencji, które budują Konwledge Graph czyli Googlowy graf wiedzy. Entities posiadają pewne cechy i atrybuty, a wyszukiwarka rozumie zależności i powiązania między nimi pozwalając na lepsze zrozumienie zapytań i treści na stronach. Dodatkowo cały mechanizm pozwala na wyświetlenie “pełniejszych” wyników i podsumowania treści dotyczących zapytania użytkownika już w wynikach wyszukiwania (wspomniane wyżej wyniki rozszerzone, tzw. snippets).
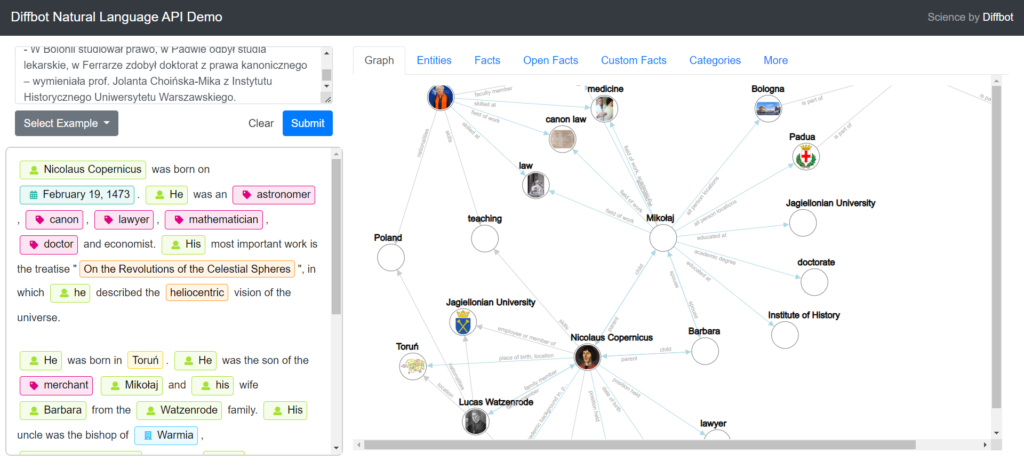
Wiemy już co nie co o semantyce i encjach oraz o relacjach między nimi. Wiemy, że encje i relacje pomiędzy nimi tworzą grafy wiedzy. Google potrafi łączyć pojęcia i wiedzieć, że należą one do jednej kategorii i wykorzystuje to. Umiejętność powiązywania artykułów oraz przypisywania ich do kategorii wiąże się z pojęciem topical authority.
Jak zadbać o topical authority na swojej stronie?
Za początek pojęcia topical authority uznaje się wdrożenie algorytmu Panda 4.0 w 2014 roku, którego głównym celem było premiowanie dobrej jakości treści i wyczyszczenie topowych pozycji wyników wyszukiwania z kopiowanych nic nie wnoszących treści. Jest to początek topical authority określanej również mianem “eksperckości” jak również “kompleksowości”. Premiowane są wyspecjalizowane w określonych tematach serwisy zapewniające duże pokrycie tematów z danej dziedziny.
Im więcej powiązanych pojęć można znaleźć na stronie docelowej oraz im większe jest pokrycie tematów tym większy topical authority, a za tym większa eksperckość serwisu w oczach Google. Google woli odsyłać usera do serwisów eksperkich.
Zadbajmy więc o pokrycie tematów – piszmy treści na tematy powiązane w ramach naszego obszaru wiedzy.
Comments